
I/O schedulers and their impact on performance

(part -1-)
Experience based on the Xperia X10mini (robyn/e10) running Jelly-Bean based MiniCM10
this post is a fork of my own post @XDA
- for a start, what are I/O schedulers ?
I/O means input&output, I/O scheduling is a method used by the operating system to decide I/O operations order and access to storage volumemain purposes are the following :
- minimize time wasted by hard disk seeks.
- prioritize certain 'processes' I/O requests.
- give a share of the disk bandwidth to each running process.
- guarantee that certain requests will be issued before a particular deadline.
taken from : here
there are a lot of I/O schedulers, only some are available in MiniCM ROMS :
| NOOP:- The NOOP scheduler inserts all incoming I/O requests into a simple, unordered FIFO queue and implements request merging. The scheduler assumes I/O performance optimization will be handled at some other layer of the I/O hierarchy; e.g., at the block device; by an intelligent HBA such as a Serial Attached SCSI (SAS) RAID controller or by an externally attached controller such as a storage subsystem accessed through a switched Storage Area Network. |
| DEADLINE:- The goal of the Deadline scheduler is to attempt to guarantee a start service time for a request. It does that by imposing a deadline on all I/O operations to prevent starvation of requests. It also maintains two deadline queues, in addition to the sorted queues (both read and write). Deadline queues are basically sorted by their deadline (the expiration time), while the sorted queues are sorted by the sector number. Before serving the next request, the Deadline scheduler decides which queue to use. Read queues are given a higher priority, because processes usually block on read operations. Next, the Deadline scheduler checks if the first request in the deadline queue has expired. Otherwise, the scheduler serves a batch of requests from the sorted queue. In both cases, the scheduler also serves a batch of requests following the chosen request in the sorted queue. |
| SIO:- scheduler is based on the deadline scheduler but it's more like a mix between no-op and deadline.In other words, SIO is like a lighter version of deadline but it doesn't do any kind of sorting, so it's aimed mainly for random-access devices (like SSD hard disks) where request sorting is no needed (as any sector can be accesed in a constant time, regardless of its physical location). |
| ANTICIPATORY:- Anticipatory scheduling is an algorithm for scheduling hard disk input/output. It seeks to increase the efficiency of disk utilization by "anticipating" synchronous read operations. |
| CFQ:-CFQ, also known as "Completely Fair Queuing", is an I/O scheduler for the Linux kernel which was written in 2003 by Jens Axboe. CFQ works by placing synchronous requests submitted by processes into a number of per-process queues and then allocating timeslices for each of the queues to access the disk. The length of the time slice and the number of requests a queue is allowed to submit depends on the IO priority of the given process. Asynchronous requests for all processes are batched together in fewer queues, one per priority. |
| BFQ:- BFQ is a proportional share disk scheduling algorithm based on the slice-by-slice service scheme of CFQ. But BFQ assigns budgets, measured in number of sectors, to tasks instead of time slices. The disk is not granted to the active task for a given time slice, but until it has exhausted its assigned budget. This change from the time to the service domain allows BFQ to distribute the disk bandwidth among tasks as desired, without any distortion due to ZBR, workload fluctuations or other factors. BFQ uses an ad hoc internal scheduler, called B-WF2Q , to schedule tasks according to their budgets. Thanks to this accurate scheduler, BFQ can afford to assign high budgets to disk-bound non-seeky tasks (to boost the throughput), and yet guarantee low latencies to interactive and soft real-time applications. |
| V(R):- The next request is decided based on its distance from the last request, with a multiplicative penalty of `rev_penalty' applied for reversing the head direction. A rev_penalty of 1 means SSTF behaviour. As this variable is increased, the algorithm approaches pure SCAN. Setting rev_penalty to 0 forces SCAN. |
thanks to dheeraj
- Which one is the best?
nobody can answer this question, but i investigated to get the following chart :
my settings are :
the Benchmarks have been run several times, and these results are average (i know, i should have made a standard deviation to show accuracy...)
|
the Benchmarks have been run several times, and these results are average (i know, i should have made a standard deviation to show accuracy...)
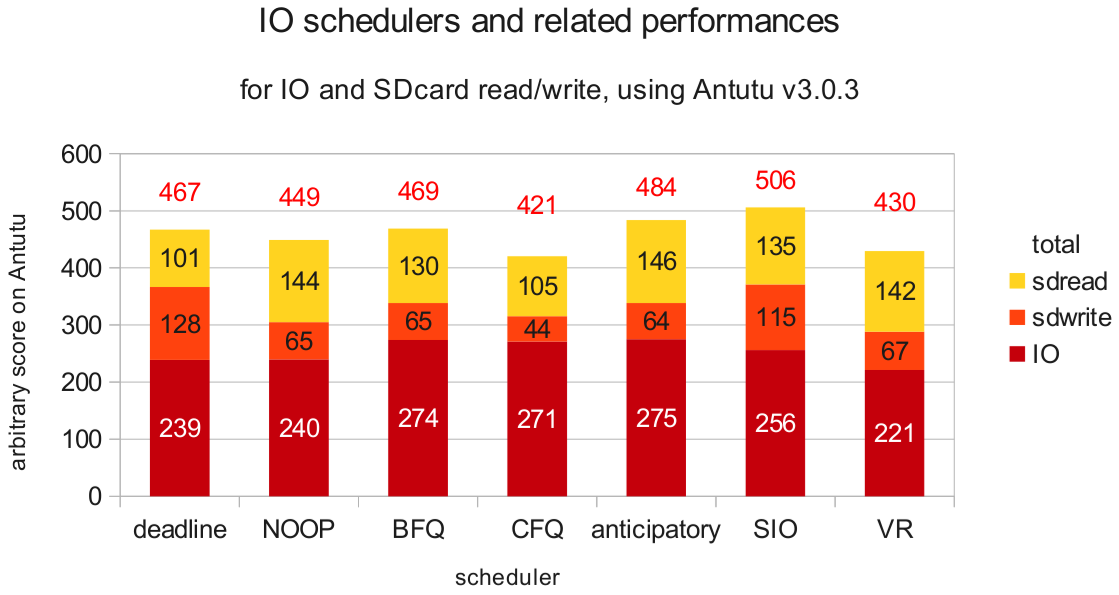
- what does the chart show us?
SIO is the more balanced scheduler, it has a good IO, and a good read/write Anticipatory has the best IO, but a bad SDwriteDeadline has the best SDwrite, but is quite average for IO and SDread
NOOP, CFQ and VR are a bit behind
- What can we conclude ?
For people using Swap on their SDcard, you need the highest SDcard read/write possible
Here the highest SDcard write is provided by Deadline, but Database I/O (IO in the chart) is important for a good and responsive system...
I think SIO is better since both write/read and IO speed are quite high
If you don't use swap, High SDcard speed is not much important, the highest I/O is better, here it would be Anticipatory or BFQ
All this might not be true on any other device (even with other robyn), to choose the best one for you, the best is to try ;)
Don't forget to read other I/O performances related posts :
No comments:
Post a Comment